考完还得记的数学知识(
高数
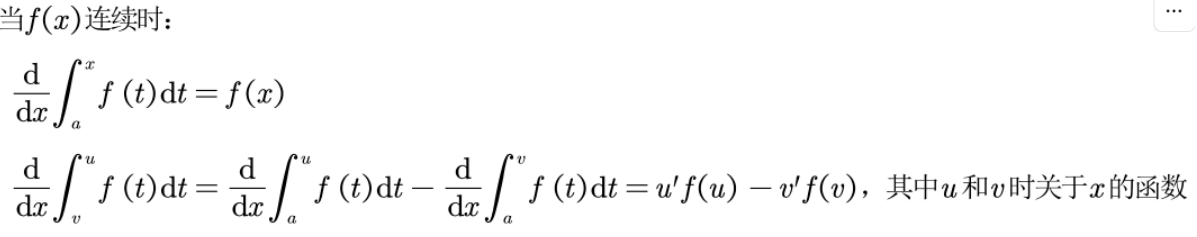
线代
[《线性代数》总复习要点、公式、重要结论与重点释疑_线性代数知识点总结及公式-CSDN博客](https://blog.csdn.net/love502504065/article/details/103983097#:~:text=本文提供《线性代数》总复习要点、公式、重要结论及释疑,配套同济版教材,由武汉大学黄正华老师整理,适合学习交流。 本文内容 配套教材:同济版:线性代数 (第五版),,来源于 武汉大学数学与统计学院信息与计算科学系黄正华 老师个人网页,分享仅供学习参考交流,相关课程更多内容通过黄老师个人网站获取,网址: http%3A%2F%2Faff.whu.edu.cn%2Fhuangzh)
求逆矩阵:矩阵逆的三种求法-CSDN博客
矩阵论:矩阵函数和矩阵求导
矩阵函数介绍
矩阵函数与通常的函数类似,但是**因变量和自变量都为 $n$ 阶矩阵。**定义如下:
定义
设一元函数 $f(x)$ 能展开为 $x$ 的幂级数:
$$
f(x) = \sum_{k=0}^{\infty} a_k x^k
$$
其中 $R$ 表示该幂级数的收敛半径。当 $n$ 阶矩阵 $A$ 的谱半径 $\rho(A) < R$ 时,把收敛矩阵幂级数 $\sum_{k=0}^{\infty} a_k A^k$ 的和称为矩阵函数,记为 $f(A)$,即:
$$
f(A) = \sum_{k=0}^{\infty} a_k A^k
$$
通过以上定义和一些基本函数,可以导出矩阵指数函数和矩阵三角函数,并推得一系列等式。
函数矩阵对矩阵的导数
我们已经在上一节中引入了矩阵函数的概念,类似地,也有微分和导数的定义。相较于标量导数,对矩阵函数的求导和微分较为复杂。在具体应用中,如梯度下降等算法,这部分内容具有重要意义,因此需要深入理解。
首先,我们将标量求导拓展到向量,对于 $\frac{\partial y}{\partial x}$,存在以下几种情况:
- $y$ 是标量:
- $x$ 是标量
- $x$ 是向量(默认为列向量,即 $n \times 1$)
- $x$ 是矩阵
- $y$ 是向量:
- 标量变元
- 向量变元
- 矩阵变元
- $y$ 是矩阵,同样有三种变元。
简单理解:
- 分子布局:分子是列向量形式,分母是行向量形式
- 分母布局:分子是行向量形式,分母是列向量形式
向量化操作
在具体分析之前,先介绍矩阵的向量化操作。例如,对矩阵 $A$ 进行列优先展开:
$$
\operatorname{vec}(A) = [a_{11}, a_{21}, …, a_{n1}, a_{12}, …, a_{nn}]^T
$$
向量变元的实值标量函数
- 行向量偏导(分子布局)
$$
\mathbf{D}_x f = \frac{\partial f}{\partial \mathbf{x}^\top} = \left[ \frac{\partial f}{\partial x_1} \quad \frac{\partial f}{\partial x_2} \quad \cdots \quad \frac{\partial f}{\partial x_n} \right]
$$
2.梯度向量偏导(分母布局)
$$
\nabla_x f = \frac{\partial f}{\partial \mathbf{x}} =
\begin{bmatrix}
\frac{\partial f}{\partial x_1} \
\frac{\partial f}{\partial x_2} \
\vdots \
\frac{\partial f}{\partial x_n}
\end{bmatrix}
$$
矩阵变元的实值标量函数
从标量求导到矩阵求导,就是分子的转置、向量化和分母的转置、向量化的各种组合。
对于分子布局:
- 分子:标量、列向量、矩阵向量化后的列向量
- 分母:标量、列向量转置后的行向量、矩阵的转置矩阵、矩阵向量化后的列向量转置后的行向量
对于分母布局:
- 分子:标量、列向量转置后的行向量、矩阵向量化后的列向量转置后的行向量
- 分母:标量、列向量、矩阵自身、矩阵向量化后的列向量
在机器学习领域,常见的主要有以下三种形式:
梯度
Hesse矩阵
$$
H(f) =
\begin{bmatrix}
\frac{\partial^2 f}{\partial x_1^2} & \frac{\partial^2 f}{\partial x_1 \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_1 \partial x_n} \
\frac{\partial^2 f}{\partial x_2 \partial x_1} & \frac{\partial^2 f}{\partial x_2^2} & \cdots & \frac{\partial^2 f}{\partial x_2 \partial x_n} \
\vdots & \vdots & \ddots & \vdots \
\frac{\partial^2 f}{\partial x_n \partial x_1} & \frac{\partial^2 f}{\partial x_n \partial x_2} & \cdots & \frac{\partial^2 f}{\partial x_n^2}
\end{bmatrix}
$$Jacobi矩阵
$$
\begin{bmatrix}
\frac{\partial y_1}{\partial x_1} & \cdots & \frac{\partial y_1}{\partial x_n} \
\vdots & \ddots & \vdots \
\frac{\partial y_m}{\partial x_1} & \cdots & \frac{\partial y_m}{\partial x_n}
\end{bmatrix}
$$
不难发现:
- 若 $f(x)$ 是一个标量函数,则 Jacobi矩阵是一个向量,等于 $f(x)$ 的梯度,Hesse矩阵是一个二维矩阵
- 若 $f(x)$ 是一个向量值函数,则 Jacobi矩阵是一个二维矩阵,Hesse矩阵是一个三维矩阵
- 梯度是 Jacobi 矩阵的特例,梯度的 Jacobi 矩阵就是 Hesse 矩阵,这其实就是一阶偏导与二阶偏导的关系
自动求导与链式法则
在实际应用问题中,标量求导中的链式法则也可以拓展到向量乃至矩阵。在使用程序计算时,库函数一般采用自动求导方式,而不是一般的符号求导或数值求导。自动求导应用了链式法则,并将整个计算过程表示成一个无环图,其中包括两种模式:
- 正向积累
- 反向传递
反向传递过程需要存储中间变量,导致内存复杂度比正向积累高。
其在实际场景中的主要应用就是神经网络,在神经网络的正向传播中,我们将输入数据通过网络层逐层传递,计算出最终的输出值。我们的目标是计算神经网络的输出 $y$ 和损失函数 $L$ 的值。而反向传播用于计算损失函数对所有网络参数的梯度。
在实际应用问题中,由于反向传播的链路过长,涉及到多次激活函数关于净输入的偏导数矩阵、当前层输入关于净输入的偏导数矩阵的连乘,如果这个矩阵的谱半径小于一,那么随着反向传播的进行,回传的梯度信号衰减地越厉害,这使得越是网络浅层的参数地梯度越微弱,那么其越难得到很好地更新。这就是梯度消失问题。